
企業が取得できるデータが膨大になった今、それをどのように分析し、活用するかが事業における大きな課題になっています。データ分析環境を作るアーキテクチャには様々な種類があり、これらを目的に沿って組み合わせることで目的の分析結果を容易に取得したり、データ活用の利便性を高めることができます。
このコラムではデータ分析環境構築における様々な手法をご紹介します。今回は分析環境のスケーラビリティと柔軟性を実現する "Salesforce+heroku+AWS+tableau" のアーキテクチャ接続についてご説明します。
今回使用するアーキテクチャ
まず、今回の例で使用するアーキテクチャと、それらの主な用途や特長についてご説明します。
◼Salesforce、heroku
Salesforceは分析対象となるユーザーのマスターデータを取得します。取得したデータをherokuへ繋ぎ、オンラインでAWSへ集約します。
◼AWS
AWSを使用することで大容量データに対するスケーラビリティを確保することができます。
◼AWS Redshift
AWS Redshiftは一括でデータを書き込み、分析のため大容量データを読み出すという処理に適しています。DBとして採用することで、データ量や用途によって変動する柔軟なリソース拡縮によるコストコントロールが可能になります。
◼AWS S3
AWS S3は安価で耐久性、可用性、スケーラビリティーに優れているため、ストレージとして利用します。
◼AWS Lambda、AWS Data Pipeline
AWS Lambda、AWS Data Pipelineは、仕様変更等に対応できる柔軟性を持ち、データを分析・加工しやすい状態に変換してBDに投入することができます。
◼tableau server(AWS EC2)、tableau desktop
tableau server(AWS EC2)、tableau desktopはBIツールとして多様な機能を持ち、操作性もシンプルであるため、様々なレベルのユーザーによる分析の実施が可能になります。
アーキテクチャの接続
上記のアーキテクチャを接続し、実際の分析環境を構築します。構築した分析環境の概要は以下の通りです。
分析環境の概要
- Salesforce+heroku+AWS+tableauのアーキテクチャ接続
- Salesforce、herokuで取得したトランザクションデータをAWS S3に保存。
- S3に保存したデータを分析・加工しやすい状態に変換するためのETLとしてAWS Lambda、AWS Data Pipelineを使用しRedshiftに格納。
- Redshiftからtableau server・tableau Desktopに接続しデータを可視化
イメージ図: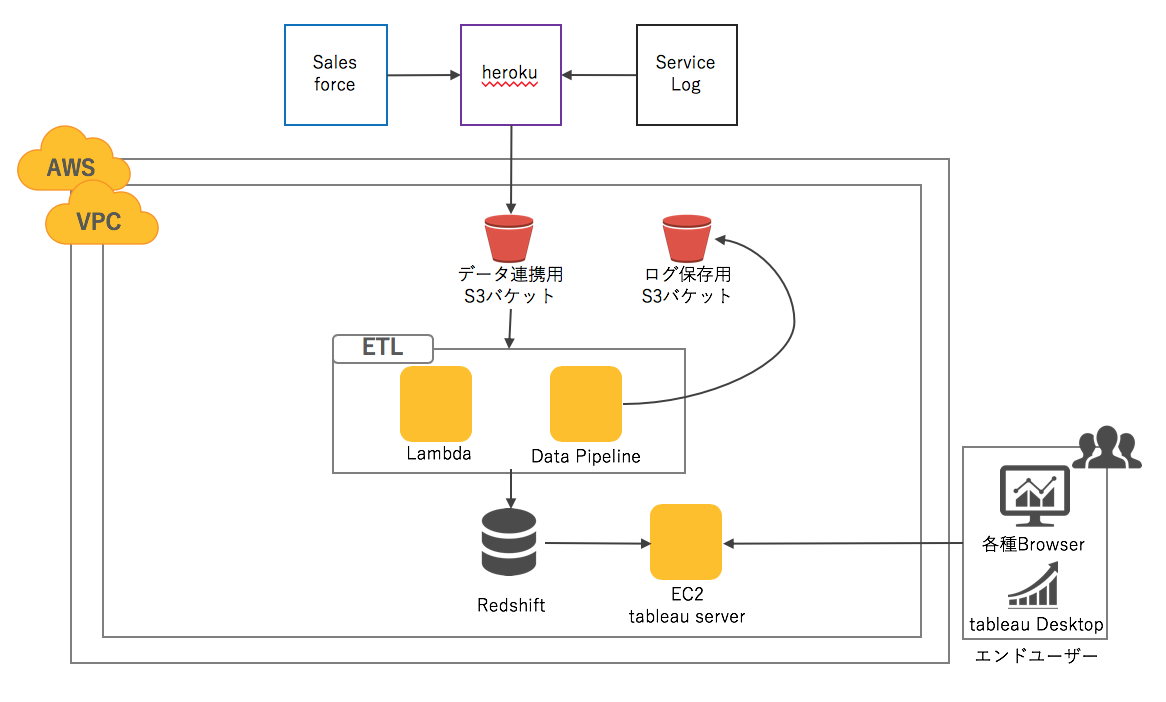
このように接続して構築した分析環境により、以下を実現することができます。
- 将来的な分析対象データ拡大に対しデータのスケーラビリティを確保する
- 分析の仕様変更等に柔軟に対応する
- 幅広いレベルの分析担当者が利用できる
- まとめ:分析の目的と使い方を見据えた環境構築が重要
分析環境のスケーラビリティと柔軟性を実現するSalesforce+heroku+AWS+tableauのアーキテクチャ接続についてご説明しました。上記の構成は分析環境構築の一例に過ぎませんが、異なる複数のアーキテクチャを組み合わせることにより、様々な目的や用途におけるデータ分析を実現することができます。アーキテクチャ接続の設計においては「データ分析の目的から逆算し、実際の使い方を想定しながら構成を組み立てる」ということが重要なポイントになります。
村上 海斗
Murakami Kaitoデータアナリティクス部 データエンジニアリンググループ データアーキテクト