
「21世紀の石油」とデータが呼ばれるように、多量・多様に変化した昨今のデータは処理・分析を施すことで有用な価値を生み出す資源と考えられています。しかし、集められたそのままのデータ(ロウデータ)では分析を行うことができません。必ず、分析をするために適した“前処理”を行わなければなりません。
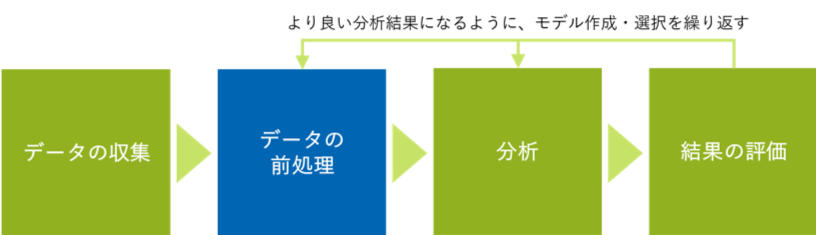
データの前処理とはロウデータを何らかの機械学習やアルゴリズムに入れて分析作業をする前に、手を加えることを指します。簡単に言うと、より精度の高い学習結果を導くためにデータをキレイに整える作業のことです。ロウデータの形式は一様でなかったり抜け漏れがあったりしますし、分析の方法に合わせたデータセットにしないとそもそも分析不可能のため、データの前処理は重要な工程となっています(図1)。では、そのような前処理の手法を本コラムで5つのポイントに分けて紹介しようと思います。
データの前処理5つのポイント
①データの使用範囲の選定
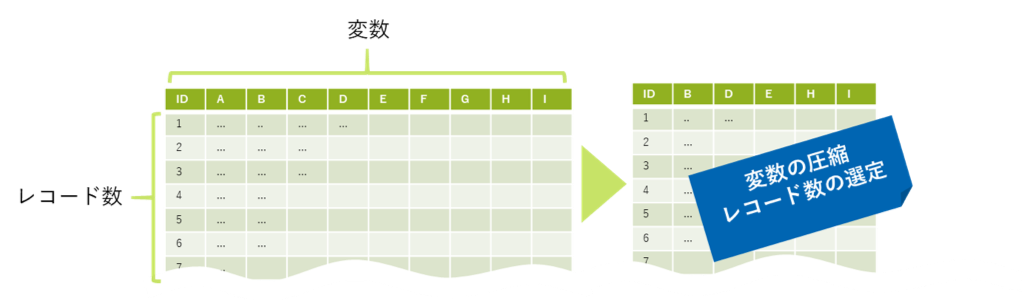
分析に用いるデータの範囲を決める処理です。必要となる変数のみに絞り、レコード数も絞る工程です。(図2)大抵はデータの全量が分析に用いられるわけではなく、分析の目的に応じて分析したいデータの範囲の指定や余分なデータ項目の削除が行われます。
②データクリーニング
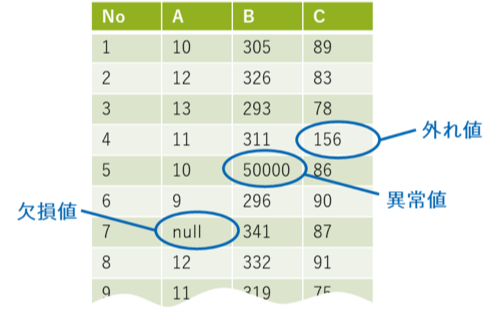
データの欠損や欠測による欠損値(欠測値)、あり得ない値の異常値、さらにほかの値と大きく離れた外れ値を見つけ、処理を行ないます。(図3)処理の際は修正が可能か、取り除くことが可能か、補間可能かなどデータに合わせて適切な選択をする必要性があります。
③正規化
データのスケーリングを行うために、一定のルールに基づいて変形し利用しやすくすることを正規化といいます。ロジスティック回帰分析等の多変量解析を行う際にしばしばデータの正規化が行われます。定番な正規化方法は、以下の2通りです。
- データの加算平均が0、分散が1となるように調整する
- データの最小値が0、最大値が1となるように調整する
どちらを用いるかは、データの分布を考慮して選択します。
④集約
複数の種類のデータが同じ意味を持つとき、データの集約やカテゴリの集約を行います。例えば言語について機械学習する時、別々に認識されてしまう“車”と“自動車”といった単語について同じ意味を持つということを指定してあげる必要があります。
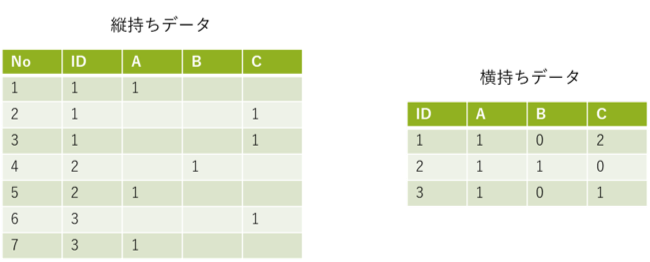
⑤テーブルの加工(縦持ちから横持ちへ)
ロウデータは1レコード毎に一つの情報しか持たない、縦持ちデータになっていることが多いです。この形式より1レコードに複数の情報を持つ横持ちデータのテーブル形式の方が見やすく、分析にも用いられやすい形式です。(図4)
ロウデータの状態や用いる分析手法によって変化しますが、主に上記のような前処理を分析前に行っています。データの情報量が少ない場合、ExcelやGoogle スプレッドシート等を用いることができますが、多量のデータを扱う際は、データ分析に用いられるツールのSQL・R・Pythonなどを用います。
※SQLとはリレーショナルデータベース管理システム(RDBMS)においてデータの操作や定義を行うための言語です。Rとは統計解析向けのプログラミング言語及びその開発実行環境です。Pythonとはデータ分析や機械学習の際によく使われるプログラミング言語です。
SQLで前処理実践
ではSQLで前処理を実践してみましょう。Google Cloud Platformが提供するビッグデータ解析サービス “BigQuery”を用いて行っていきます。今回はBigQuery内のサンプルデータを使用しました。
(参照:Google Cloud/メジャーリーグ ベースボール データ)
baseball スキーマ内のgames_wide から、7月~9月の3ヶ月間、各選手(バッター)が継続的に試合出場しているか知りたいとします。
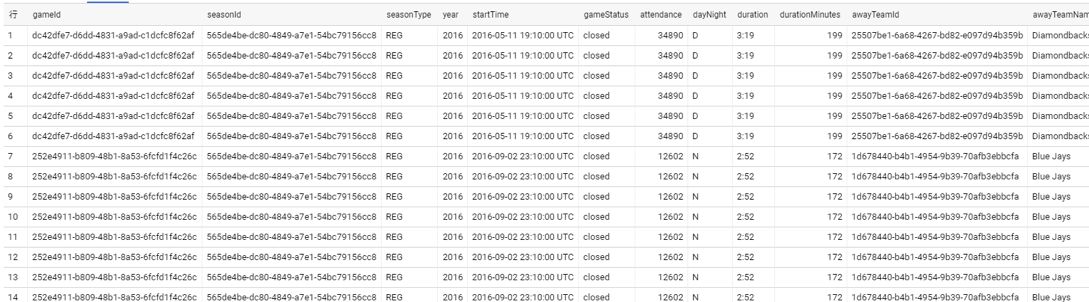
データはピッチャーの1投球ごとに縦持ちデータとして記録されています。項目としては、試合開始日時、バッターID、バッターの名前、ピッチャーID、投球日時、1投球に対する結果etc...。この縦持ちデータをバッターごと、月ごと(7月~9月)にどのくらい継続出場していたのかがわかる横持データに変換しようと思います。この時必要な前処理の作業は下記の2点になります。
①データの使用範囲の選定→測定期間7月~9月、1ヶ月間ごとでのチェックポイント
⑤テーブル加工→縦持ちデータを圧縮した横持データに加工
では実行してみましょう。コードは下記のように書いてみました。
with mothly_hitter_data as (
select hitterId,
max(case when startTime between '2016-01-01 00:00:00' and '2016-01-31 23:59:59' then 1 else null end) as JAN,
max(case when startTime between '2016-02-01 00:00:00' and '2016-02-29 23:59:59' then 1 else null end) as FEB,
max(case when startTime between '2016-03-01 00:00:00' and '2016-03-31 23:59:59' then 1 else null end) as MAR,
max(case when startTime between '2016-04-01 00:00:00' and '2016-04-30 23:59:59' then 1 else null end) as APR,
max(case when startTime between '2016-05-01 00:00:00' and '2016-05-31 23:59:59' then 1 else null end) as MAY,
max(case when startTime between '2016-06-01 00:00:00' and '2016-06-30 23:59:59' then 1 else null end) as JUNE,
max(case when startTime between '2016-07-01 00:00:00' and '2016-07-31 23:59:59' then 1 else null end) as JULY,
max(case when startTime between '2016-08-01 00:00:00' and '2016-08-31 23:59:59' then 1 else null end) as AUG,
max(case when startTime between '2016-09-01 00:00:00' and '2016-09-30 23:59:59' then 1 else null end) as SEPT
from `bigquery-public-data.baseball.games_wide`
group by hitterId)
select hitterId,
case when JUNE is null then '0か月継続'
when JUNE = 1 and MAY is null then '1か月継続'
when JUNE = 1 and MAY = 1 and APR is null then '2か月継続'
when JUNE = 1 and MAY = 1 and APR = 1 and MAR is null then '3か月継続'
when JUNE = 1 and MAY = 1 and APR = 1 and MAR = 1 and FEB is null then '4か月継続'
when JUNE = 1 and MAY = 1 and APR = 1 and MAR = 1 and FEB = 1 and JAN is null then '5か月継続'
when JUNE = 1 and MAY = 1 and APR = 1 and MAR = 1 and FEB = 1 and JAN = 1 then '6か月以上継続'
else null end as JULY,
case when JULY is null then '0か月継続'
when JULY = 1 and JUNE is null then '1か月継続'
when JULY = 1 and JUNE = 1 and MAY is null then '2か月継続'
when JULY = 1 and JUNE = 1 and MAY = 1 and APR is null then '3か月継続'
when JULY = 1 and JUNE = 1 and MAY = 1 and APR = 1 and MAR is null then '4か月継続'
when JULY = 1 and JUNE = 1 and MAY = 1 and APR = 1 and MAR = 1 and FEB is null then '5か月継続'
when JULY = 1 and JUNE = 1 and MAY = 1 and APR = 1 and MAR = 1 and FEB = 1 then '6か月以上継続'
else null end as AUG,
case when AUG is null then '0か月継続'
when AUG = 1 and JULY is null then '1か月継続'
when AUG = 1 and JULY = 1 and JUNE is null then '2か月継続'
when AUG = 1 and JULY = 1 and JUNE = 1 and MAY is null then '3か月継続'
when AUG = 1 and JULY = 1 and JUNE = 1 and MAY = 1 and APR is null then '4か月継続'
when AUG = 1 and JULY = 1 and JUNE = 1 and MAY = 1 and APR = 1 and MAR is null then '5か月継続'
when AUG = 1 and JULY = 1 and JUNE = 1 and MAY = 1 and APR = 1 and MAR = 1 then '6か月以上継続'
else null end as SEPT
from mothly_hitter_data;
すると下記のようなテーブルが作成できました。
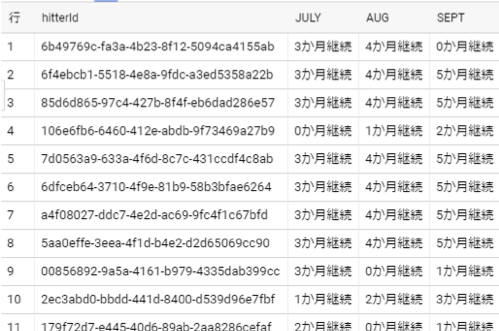
選手のIDごとに、7~9月に試合に継続出場したかどうか見ることができるようになりました。以上が今回の作業での前処理です。前処理によってデータを見やすい状態することができました。さらに例えば特定の選手だけ指定したいときは、下記の句を追加することで見つけられます。
where hitterId = '177bb129-6ddd-4773-be3d-e5af23e33bb8' --イチローのID
最後に
今回のBigQueryでの集計の例だけでなく、ロジスティック回帰分析などに用いるデータも、SQL・R・Python等で加工が可能です。適切な前処理によって、データが扱いやすくなるだけでなく分析の精度も向上します。分析結果が怪しい時にはその前の工程の前処理を疑ってみるのも一つの手立てかもしれません。
この記事を書いた人
南條 光香
Hikaru Nanjoデータアナリティクス部 アシスタント・データサイエンティスト
事業会社でキャリアをスタートし、データサイエンティストとしてウフル・データアナリティクス部に参画。主にRやSQL等を使ってデータの抽出・加工から分析・機械学習などを担当している。